
About Me
I am a Ph.D. candidate in Electrical and Computer Engineering at the University of Maryland, College Park, working with Prof. Shuvra S. Bhattacharyya in the Maryland DSPCAD Research Group. I received my M.S. degree from the Graduate Institute of Electronics Engineering at National Taiwan University, where I was advised by Prof. Liang-Gee Chen in the DSPIC Lab. I earned my B.S. degree in Electrical Engineering from National Taiwan University.
Research Overview
My research focuses on synthetic data generation and utilization, with the goal of reducing the human effort required for data annotation and making machine learning more accessible across a wide range of applications. These include aerial-view perception, human pose analysis, and medical imaging—domains where labeled data are often scarce or expensive to obtain, and computational resources may be limited. To advance this goal, I explore a broad range of machine learning paradigms, including game engine–based data synthesis, domain adaptation, generative modeling (e.g., diffusion models), and multimodal large language models.
Below is a summary of my research contributions, organized by methodology and color-coded by application domain:
• Generative Modeling (e.g., Diffusion Models): SynPoseDiv [ICIP'25]
• Multimodal Large Language Models: AutoComPose [ICCV'25]
• Semi-, Weakly-, and Self-Supervised Learning: MEMO [BOEx'24], What Synthesis is Missing [ICCV'19], D+T-Net [MS Thesis]
• Miscellaneous: EgoFall [ICASSP'24, TNSRE'25], DDHC [WHISPERS'21]
Publications

SynPlay: Large-Scale Synthetic Human Data with Real-World Diversity for Aerial-View Perception
Jinsub Yim, Hyungtae Lee, Sungmin Eum, Yi-Ting Shen, Yan Zhang, Heesung Kwon, and Shuvra S. Bhattacharyya
WACV 2026
[arXiv] [Project]
We present Synthetic Playground (SynPlay), a large-scale synthetic human dataset with diverse motions and camera viewpoints—especially aerial views—that significantly improves human identification performance in challenging, data-scarce scenarios like few-shot learning and cross-domain adaptation.
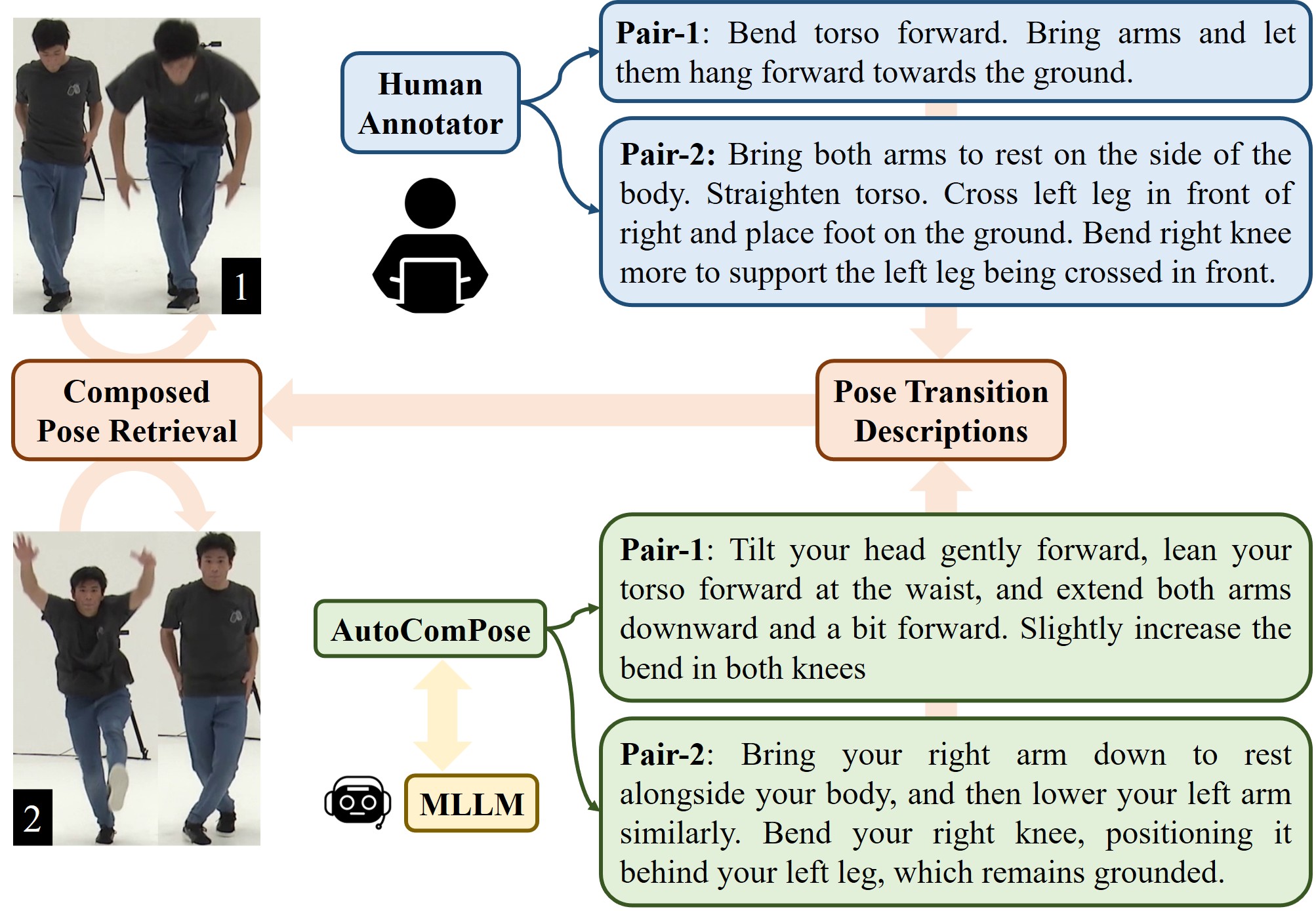
AutoComPose: Automatic Generation of Pose Transition Descriptions for Composed Pose Retrieval Using Multimodal LLMs
Yi-Ting Shen*, Sungmin Eum*, Doheon Lee, Rohit Shete, Chiao-Yi Wang, Heesung Kwon, and Shuvra S. Bhattacharyya (* equal contribution)
ICCV 2025
[arXiv] [Code]
We introduce AutoComPose, the first framework to automatically generate pose transition annotations using multimodal large language models, significantly improving composed pose retrieval performance while reducing reliance on costly human labeling.
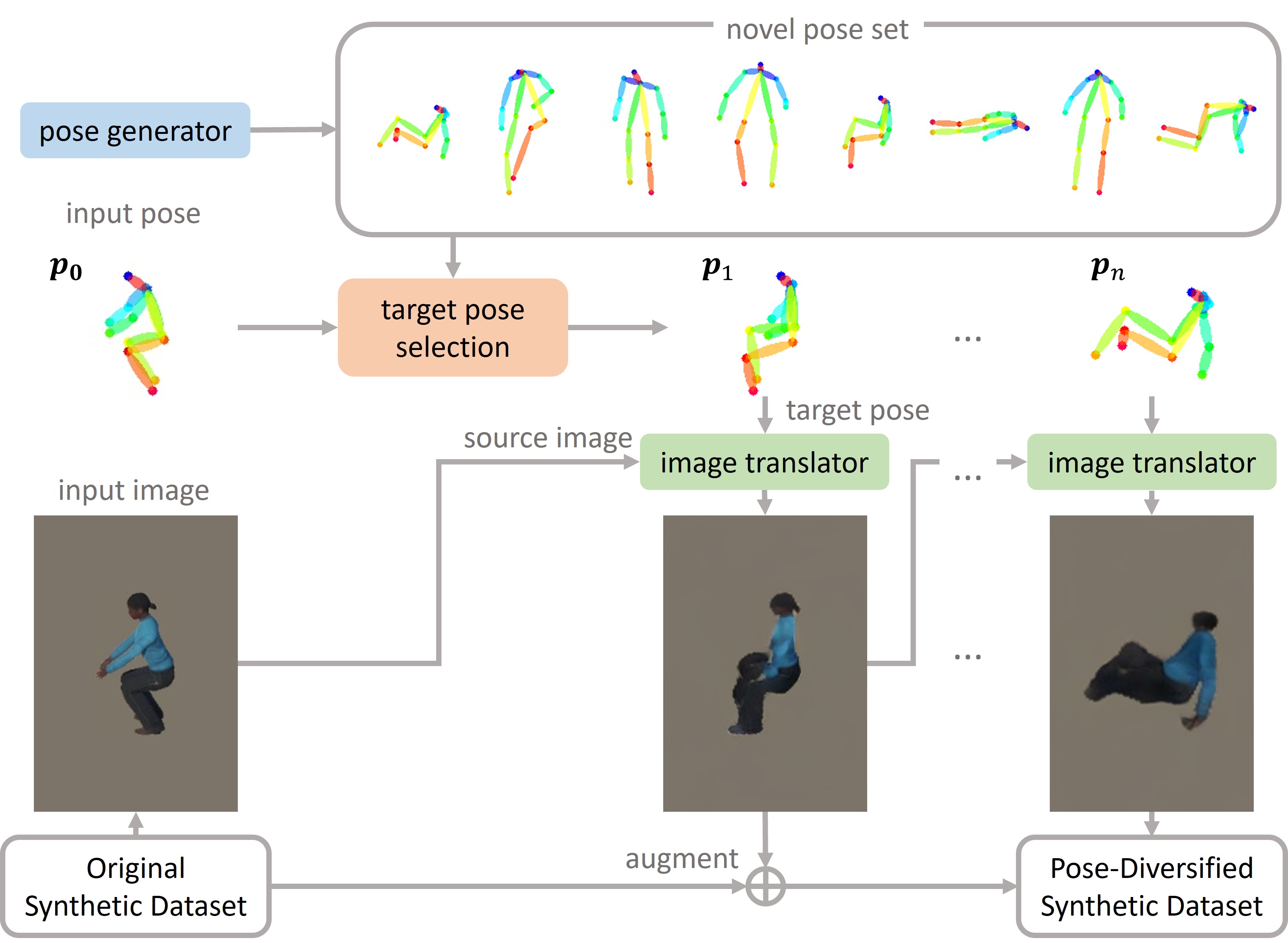
Diversifying Human Pose in Synthetic Data for Aerial-view Human Detection
Yi-Ting Shen*, Hyungtae Lee*, Heesung Kwon, and Shuvra S. Bhattacharyya (* equal contribution)
ICIP 2025
[arXiv]
We introduce SynPoseDiv, a novel framework that enhances synthetic aerial-view datasets by generating realistic and diverse 3D human poses using diffusion models and image translation, leading to significantly improved detection accuracy, especially in low-shot scenarios.
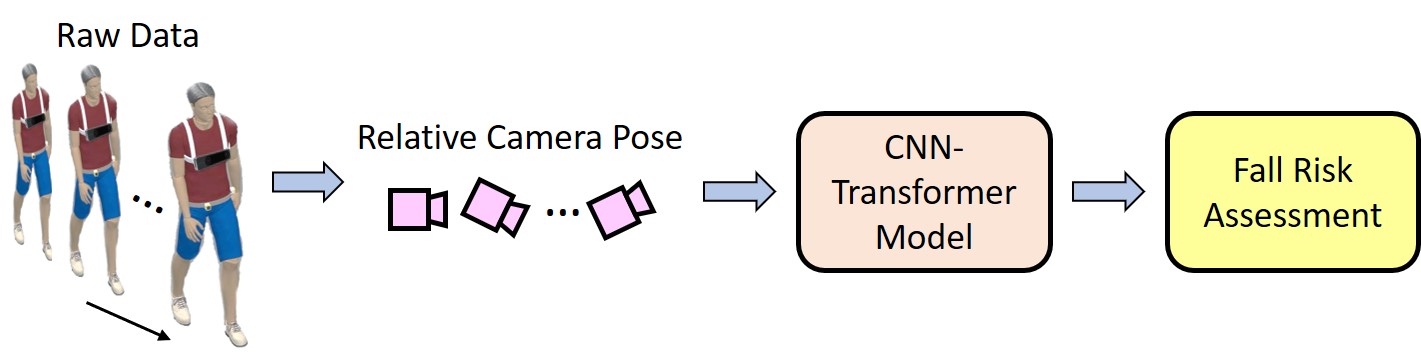
EgoFall: Real-time Privacy-Preserving Fall Risk Assessment with a Single On-Body Tracking Camera
Chiao-Yi Wang, Faranguisse Kakhi Sadrieh, Yi-Ting Shen, Giovanni Oppizzi, Li-Qun Zhang, and Yang Tao
ICASSP 2024
IEEE Transactions on Neural Systems and Rehabilitation Engineering 2025
[Conference Paper] [Journal Extension]
We propose EgoFall, a real-time, privacy-preserving fall risk assessment system that uses a chest-mounted camera and a lightweight CNN-Transformer model to analyze ego-body motion, enabling personalized fall prevention without relying on multiple wearable sensors.
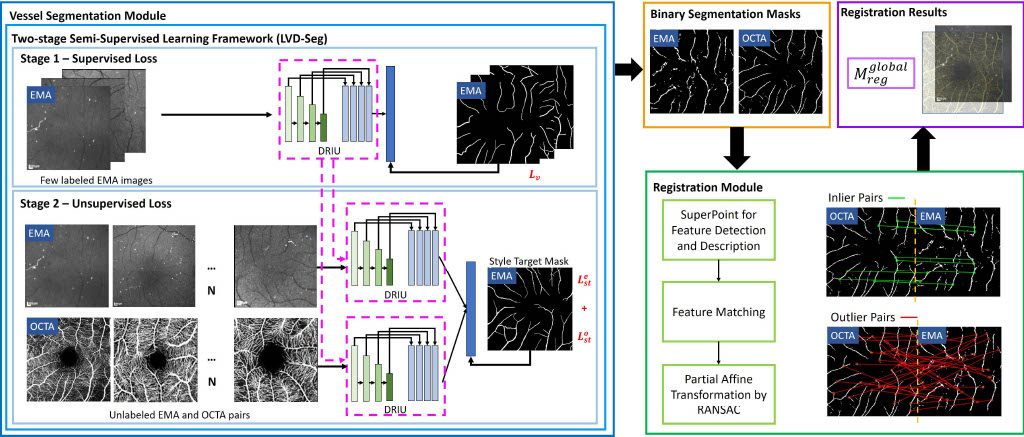
MEMO: Dataset and Methods for Robust Multimodal Retinal Image Registration with Large or Small Vessel Density Differences
Chiao-Yi Wang, Faranguisse Kakhi Sadrieh, Yi-Ting Shen, Shih-En Chen, Sarah Kim, Victoria Chen, Achyut Raghavendra, Dongyi Wang, Osamah Saeedi, and Yang Tao
Biomedical Optics Express 2024
[Paper] [Dataset]
We introduce MEMO, the first public multimodal EMA-OCTA retinal image dataset, and propose VDD-Reg, a deep learning framework that enables robust retinal image registration across large vessel density differences, advancing accurate capillary blood flow measurement for ocular disease diagnosis.
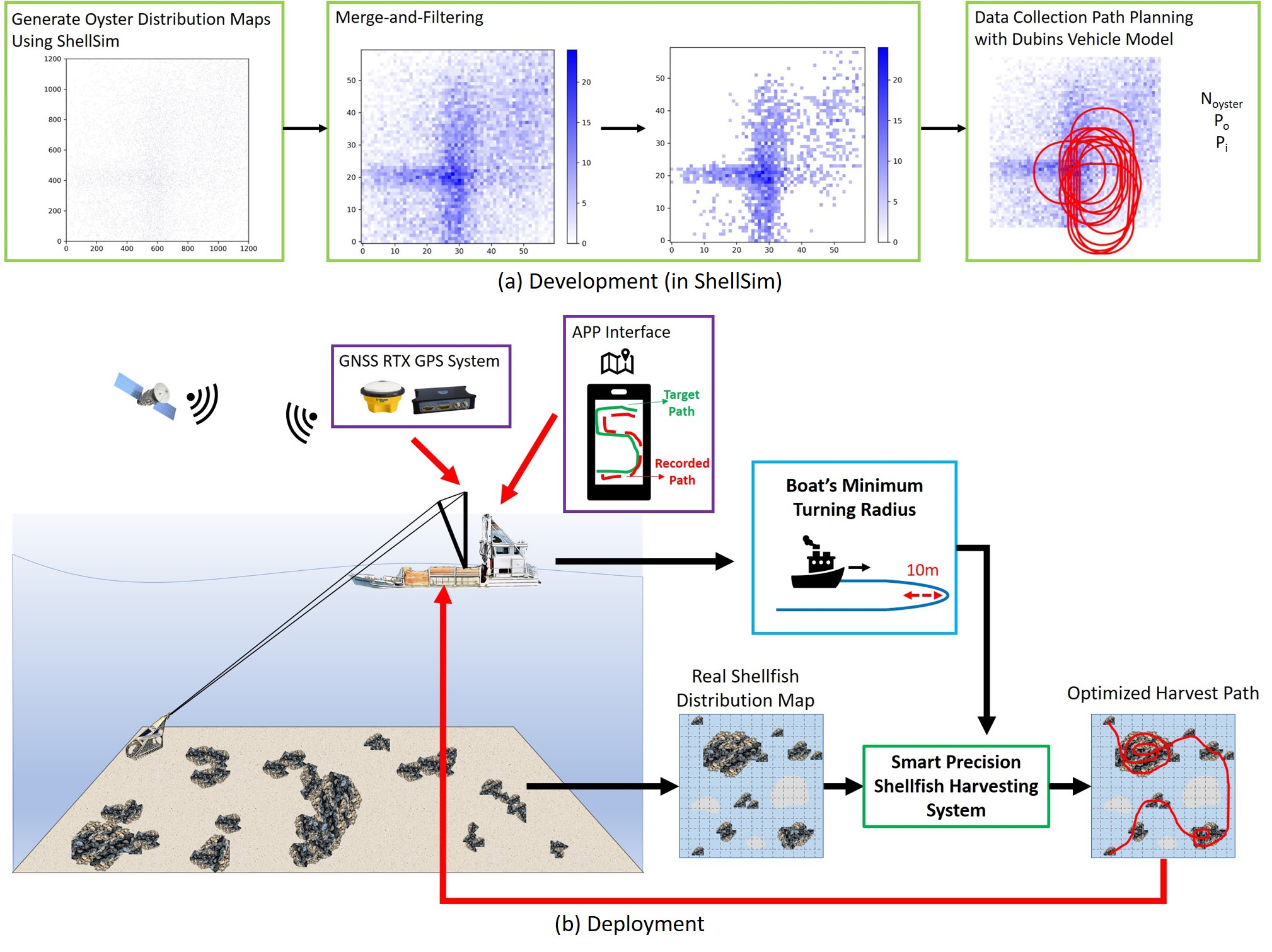
ShellCollect: A Framework for Smart Precision Shellfish Harvesting Using Data Collection Path Planning
Chiao-Yi Wang, ADP Guru Nandhan, Yi-Ting Shen, Wei-Yu Chen, Sandip Sharan Senthil Kumar, Alexander Long, Alan Williams, Gudjon Magnusson, Allen Pattillo, Don Webster, Matthew Gray, Miao Yu, and Yang Tao
IEEE Access 2024
[Paper]
We present ShellCollect, the first smart precision shellfish harvesting framework that plans efficient dredging paths based on underwater oyster distributions, significantly improving harvesting efficiency, and validate its effectiveness through simulation and real-world field tests.
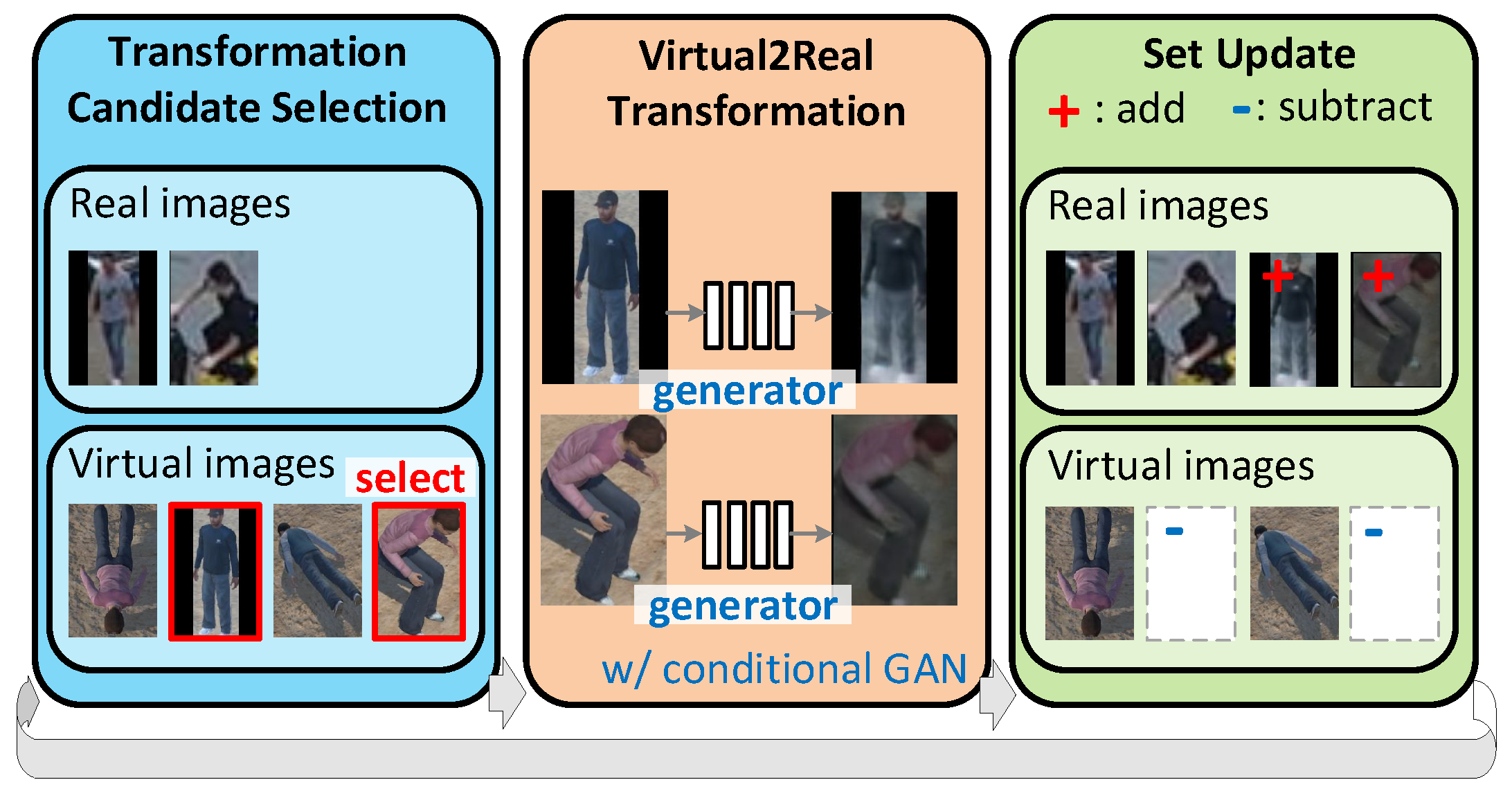
Progressive Transformation Learning for Leveraging Virtual Images in Training
Yi-Ting Shen*, Hyungtae Lee*, Heesung Kwon, and Shuvra S. Bhattacharyya (* equal contribution)
CVPR 2023
Selected as a Highlight among the top 10% of accepted papers
[arxiv] [Code] [Video]
We introduce Progressive Transformation Learning (PTL), a novel framework that progressively transforms and selects virtual UAV images based on domain gap measurements to enhance realism and improve object detection performance, particularly in low-data and cross-domain scenarios.

Archangel: A Hybrid UAV-based Human Detection Benchmark with Position and Pose Metadata
Yi-Ting Shen, Yaesop Lee, Heesung Kwon, Damon M Conover, Shuvra S. Bhattacharyya, Nikolas Vale, Joshua D Gray, G Jeremy Leong, Kenneth Evensen, and Frank Skirlo
IEEE Access 2023
[arxiv] [Paper] [Dataset]
We introduce Archangel, the first UAV-based object detection dataset combining real and synthetic data with detailed metadata on UAV position and object pose, enabling precise model diagnosis and providing new insights into learning robust, variation-invariant detection models.
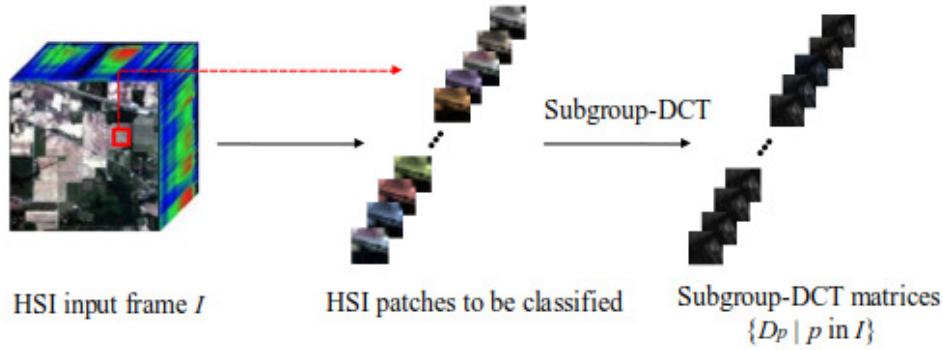
DCT-based Hyperspectral Image Classification on Resource-Constrained Platforms
Eung-Joo Lee, Yi-Ting Shen, Lei Pan, Zhu Li, and Shuvra S. Bhattacharyya
WHISPERS 2021
[Paper]
We propose a flexible deep learning framework (DDHC) for hyperspectral image classification that learns from discrete cosine transform (DCT) coefficients, enabling efficient accuracy–computation trade-offs and streamlined deployment on resource-constrained platforms.
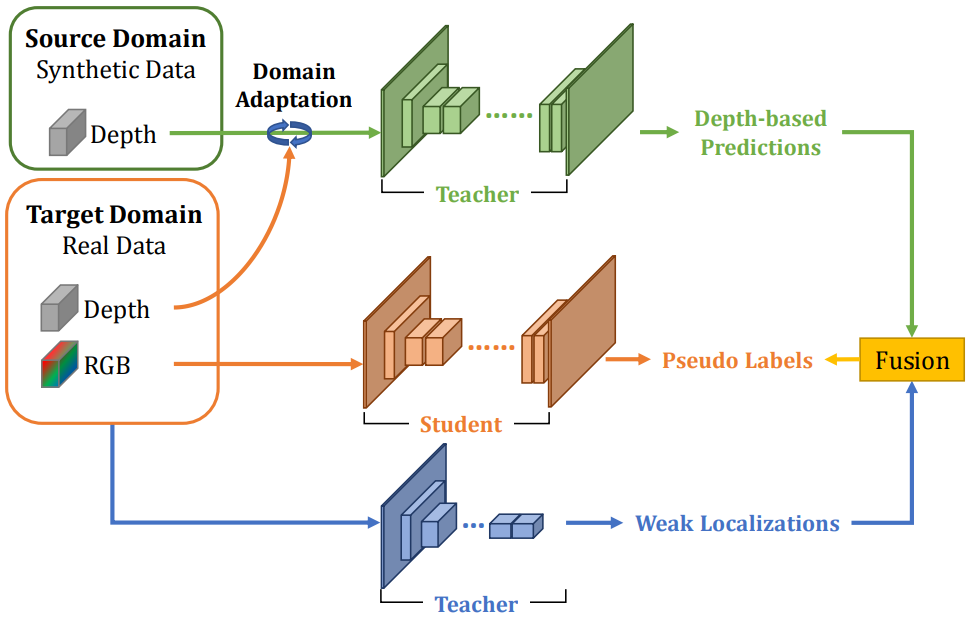
What Synthesis is Missing: Depth Adaptation Integrated with Weak Supervision for Indoor Scene Parsing
Keng-Chi Liu, Yi-Ting Shen, Jan P Klopp, and Liang-Gee Chen
ICCV 2019
[arxiv]
We propose a novel teacher-student framework for weakly supervised scene parsing that combines synthetic depth-based domain transfer with image-level weak labels via a contour-based integration scheme, significantly narrowing the performance gap to fully supervised methods while reducing annotation effort.
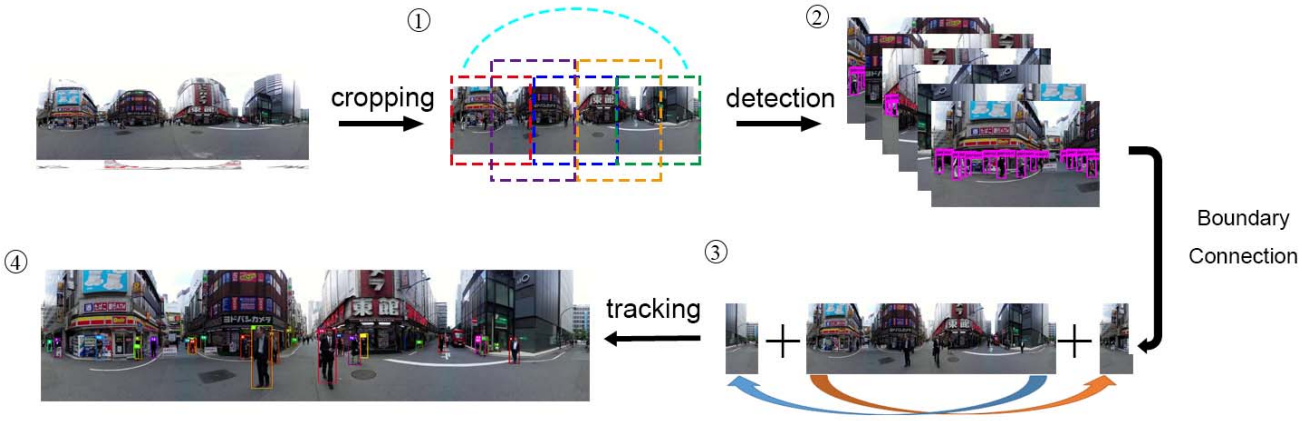
Simple Online and Realtime Tracking with Spherical Panoramic Camera
Keng-Chi Liu*, Yi-Ting Shen*, and Liang-Gee Chen (* equal contribution)
ICCE 2018
[Paper] [Dataset]
We propose a simple yet effective real-time multi-object tracking method tailored for 360-degree panoramic videos, achieving significant performance gains over baselines and introducing two new datasets for comprehensive evaluation.

3D Perception Enhancement in Autostereoscopic TV by Depth cue for 3D Model Interaction
Yi-Ting Shen, Guan-Lin Liu, Sih-Sian Wu, and Liang-Gee Chen
ICCE 2016
[Paper]
We present an enhanced autostereoscopic TV system that incorporates Human Visual System-based depth cues to significantly improve 3D perception—doubling viewer depth perception compared to conventional systems—and demonstrate its effectiveness through an interactive 3D model application.
Preprints
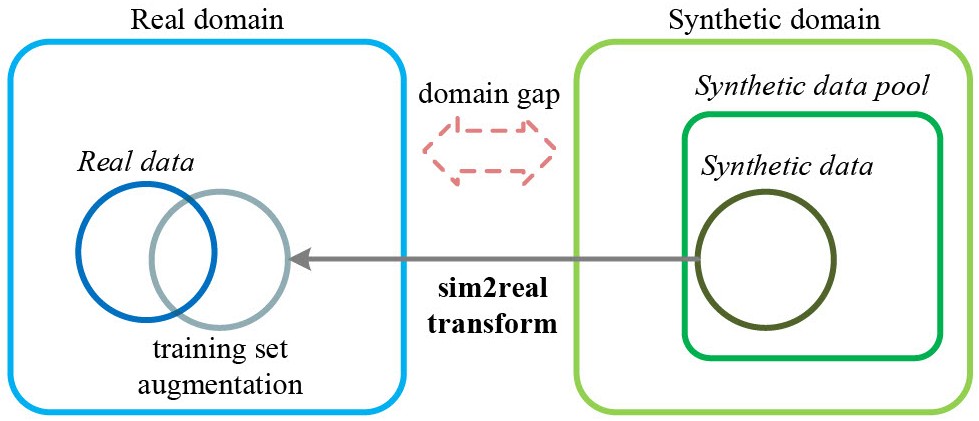
Exploring the Impact of Synthetic Data for Aerial-view Human Detection
Hyungtae Lee*, Yan Zhang*, Yi-Ting Shen*, Heesung Kwon, and Shuvra S. Bhattacharyya (* equal contribution)
[arXiv]
We investigate key factors influencing sim-to-real transfer in UAV-based human recognition and reveal how strategic selection of synthetic data can significantly improve model performance and domain generalization, offering insights that challenge common misconceptions about synthetic data usage.
Thesis

Self-Supervised Learning of Domain-Specific Depth for Transferable Traversability Estimation with a Single Fisheye Camera
Yi-Ting Shen
Master's Thesis
Advisor: Liang-Gee Chen, Ph.D.
[Online] [Thesis] [Report] [Slides]
We propose a two-stage convolutional neural network (D+T-Net) for traversability estimation that leverages domain-specific depth estimation and a universal classifier to achieve high accuracy and strong cross-domain transferability using only a single fisheye camera, making it ideal for real-world, resource-constrained robotic applications.